
PhyAAt Dataset
Description
EEG Channels: 'AF3', 'F7', 'F3', 'FC5', 'T7', 'P7', 'O1', 'O2', 'P8', 'T8', 'FC6', 'F4', 'F8', 'AF4'
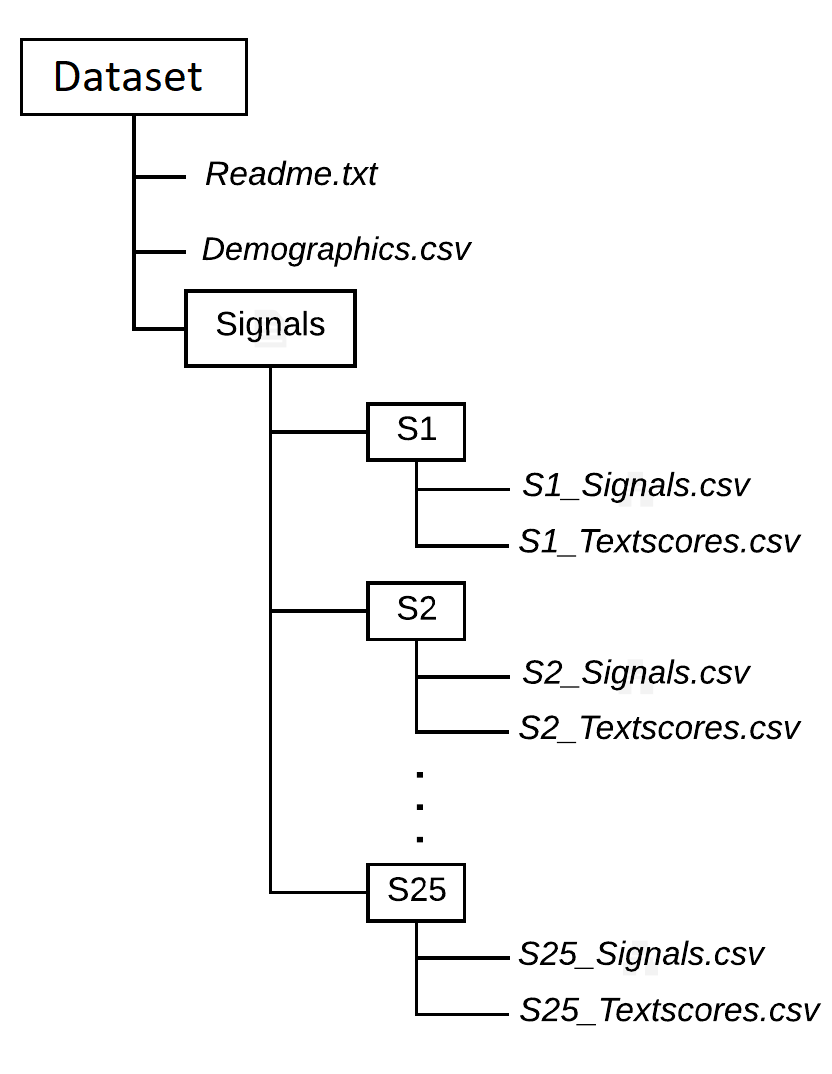
File structure and field names in files
As shown in figure below, The dataset contain 25 directories, one for each subject. Each directory contain Signals.csv and Textscores.csv files.
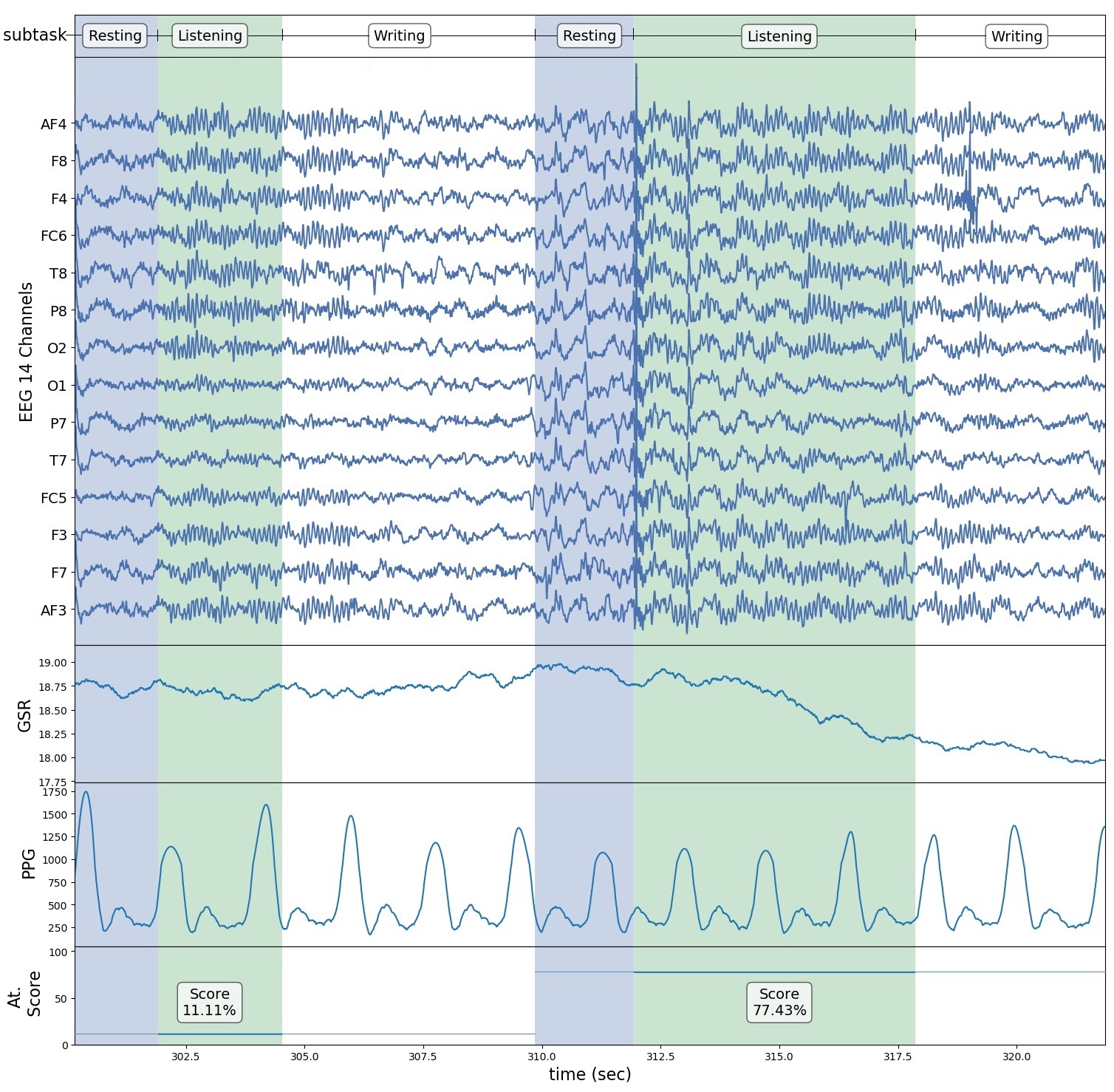
Signal File
Signals.csv file contain all the 19 streams of signals and lebels. Following are coulumn names
- TimeStamp : Time stamp - normalize to start with 00 Hour
- ‘AF3’ ..’AF4’ : 14 Channels of EEG Signals
- PPG : Raw PPG signal
- BPM : Pulse Rate in Beats per minute
- IBI : Inter-Beat-Interval
- 0 : Zero (Just a divider for alignment)
- gsrRaw : instantnious GSR signal
- gsrLPF : Lowpass GSR Signals (Moving averaged of past 100 samples)
- Label_N: Noise Levels [-6,-3,0,3,6,1000] dB
- Label_S: Semanticity Label: 0-Semantic, 1-Non-semantic
- Label_T: Task: 0-Listenting, 1-Writing, 2-Resting
- CaseID : CaseID An identyfier code for experimental condition, encoded value of noise level and semanticity
Labels and CaseID also include value -1, for the signals before first listening task started
Textscore file
Textscore file contain, TimeStamp, Attention Score (Correctness Score), Total Words and CorrectWords, along with CaseID, SNR and Semanticity Label for each listening segment. The number of attention scores and number of listening segments are same. At very few occasions, due to bad connection recording of physiological signals were dropped, so a very few segments among all the subjects might not have sufficient samples to process but they still have attention score and other labels.
Download the physiological dataset
Python
To download the dataset, install phyaat library and download through it.
pip install phyaat
import phyaat as ph
# to download dataset of subject 1 in given path 'dirpath'
dirPath = ph.download_data(baseDir='../PhyAAt_Data', subject=1,verbose=0,overwrite=False)
# to download dataset of all the subjects
dirPath = ph.download_data(baseDir='../PhyAAt_Data', subject=-1,verbose=0,overwrite=False)
Manually
If you are using other programming framework such as matlab or R, Download dataset manually from Github repository and extract all the csv files.
Tabular data
Download tabular data for statistical analysis
For statistical analysis of attention score with auditory conditions, download a compiled datasheet as csv file.
1. Download Tabular Data File here
This file includes noise level, sementicity, length of stimulus and attenstion score for each subject, averaged across each experimental setting.
The total number of different experiment conditions are $6\times 2 \times 3 = 36$, so in this file there are 36 rows for each subject, totaling to $36 \times 25 = 900$ rows.
File structure is as follow:
| SID | SNRdB | Semanticity | LengthStim | AttentionScore |
|---|---|---|---|---|
| S1 | -6 | 1 | L3 | 11.18881119 |
| S3 | 1000 | 0 | L2 | 86.16071429 |
| S5 | 6 | 0 | L1 | 75 |
| . | . | . | . | . |
Here:
- SID : Subject ID, S1 .. S25
- SNRdB : Noise Level in dB, -6,-3,0,3,6, 1000. Here 1000 is for noise free
- Semanticity: Semanticity, 0-Semantic, 1-Non Semantic
- LengthStim: Length of stimulus, L1-small, L2-medium, and L3-long
- AttentionScore: Average Attention score for given condition (average score of multiple stimuli in same auditory condition). Attention score ranges from 0 to 100, as a level of attention.
For data on each trial for each subject, $144 \times 25 \approx 3597$ , download file here .
In addtion, a file with demographics and self rating of language can be download too.
2. Download Demographic Data File
This data includes age-group, sex, and self-reported ratings English Langauge skill in terms of reading, writing, speaking, and listening, for each subject on 5-point scale.
File structure is as follow:
| SID | AgeGroup | Sex | Read | Write | Speak | Listen |
|---|---|---|---|---|---|---|
| S1 | 26 to 30 | Male | 4 | 4 | 3 | 4 |
| S4 | 26 to 30 | Female | 5 | 4 | 4 | 4 |
| . | . | . | . | . | . | . |
| S25 | 21 to 25 | Male | 5 | 5 | 5 | 5 |
Here:
- SID : Subject ID, S1 .. S25
- AgeGroup : Age Group: 16-20, 21-25, 26-30, 31-35, 36-40
- Sex: Male, Female, Others
- Read/Write/Speak/Listen: 1 to 5, self-reported reading, writing, speaking, and listening skills of English Language. 1-very poor, 5-excellent.